Elevate Care and Accelerate Discovery with Traceable & Explainable Digital Twins
The Agentic AI platform to build Digital Twins that patients talk to, clinicians trust, and researchers rely on
From Patient Data to Trusted Digital Twins
T2R2 Traceability Backend powered by Akka
2025-12-01
AKKA, the perfect PaaS solution for T2R2
LLAAMA PLATFORM, Agentic AI for Life Science
2025-09-10
LLAAMA PLATFORM, a multi-agent framework for Life Science
One Platform. Two Critical Impacts
-
For Healthcare Providers & Patients: A 24/7 intelligent companion. The Patient Digital Twin guides patients through recovery (e.g. pre-op prep, post-op care) and collects vital data, acting as a tireless extension of your clinical team.
-
For Pharma & Life Sciences: A high-fidelity simulation. Model patient trajectories with precision, run in silico trials, and gather real-world evidence with full regulatory traceability.

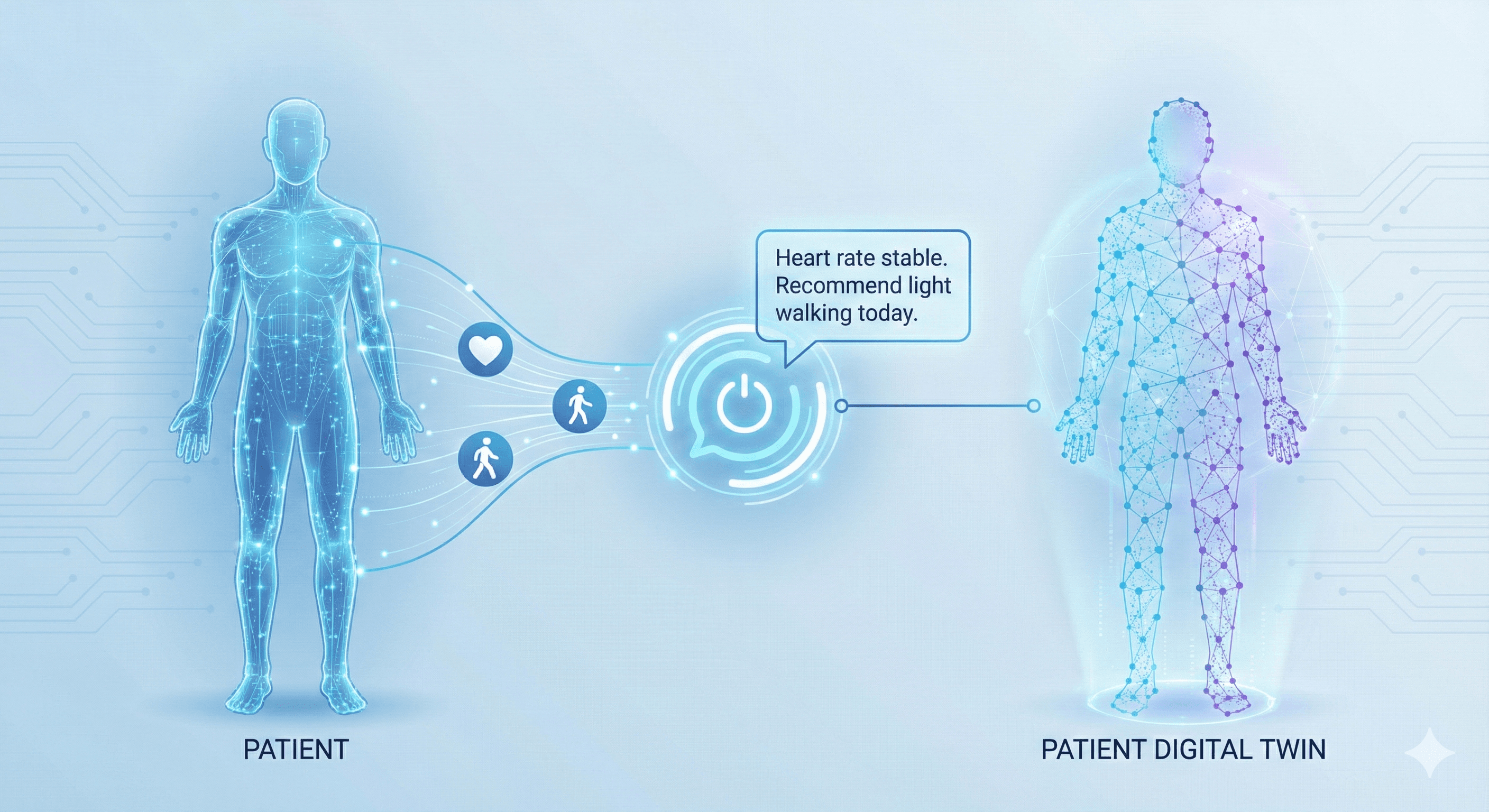
Interactive Patient Digital Twins
More Than a Model—A Partner in Care. Our Digital Twins are active agents
-
For Patients: The Twin explains complex medical procedures (like surgery steps) in plain language and answers anxieties 24/7.
-
For Staff: It autonomously interviews patients to gather history or symptom updates, summarizing the data so the doctor can focus on diagnosis, not data entry.
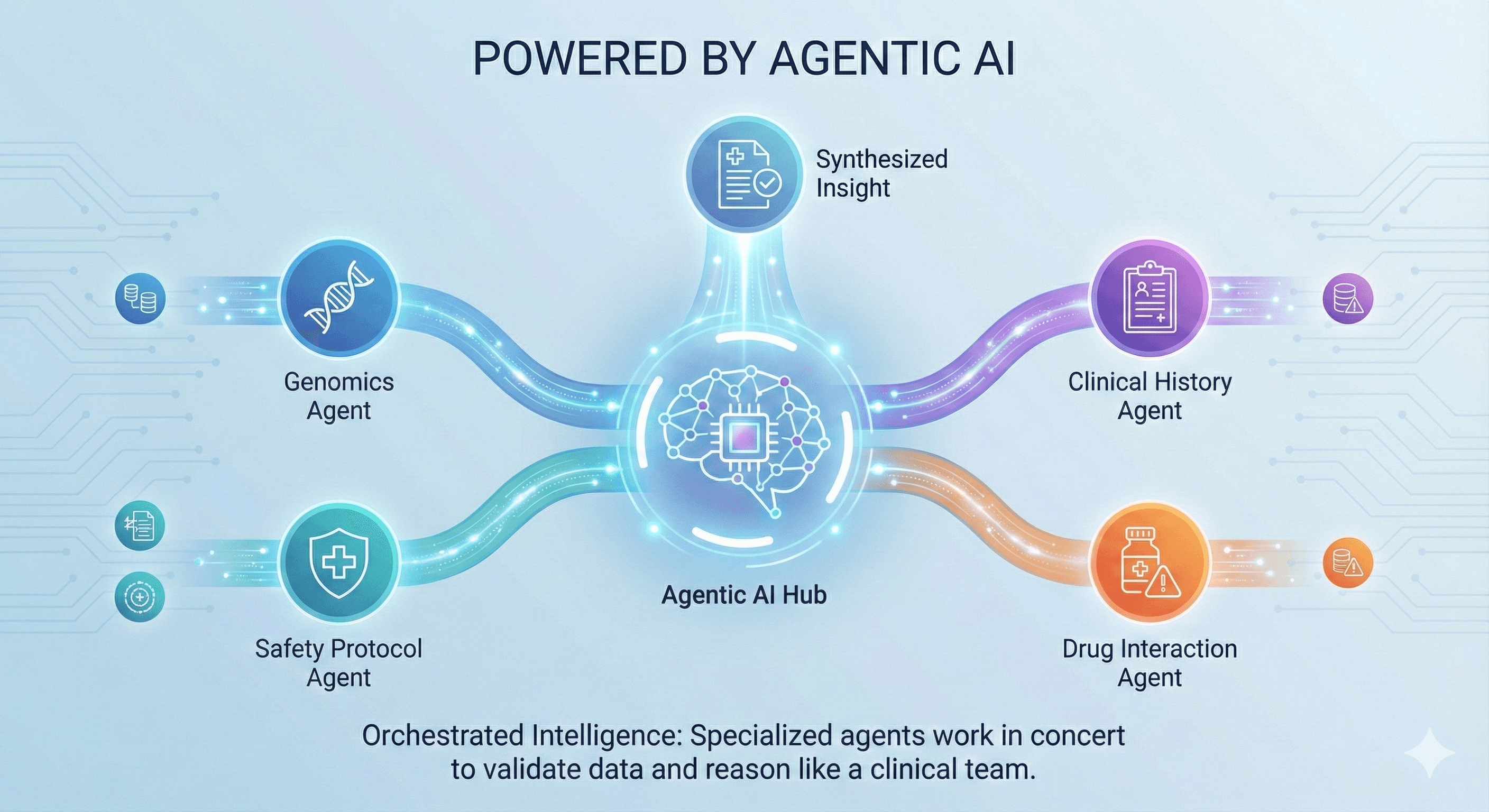
Powered by Agentic AI
The "Virtual Clinical Colleague."
Standard chatbots hallucinate; Llaama’s Agentic AI platform reasons.
It works like a specialized care team:
-
One agent manages the patient conversation with empathy.
-
One agent checks the medical guidelines.
-
One agent updates the clinical record.
The Result: Doctors get accurate, summarized insights, and patients get safe, verified answers—never guesses.
Traceability & Safety (T2R2™)
Trust is Non-Negotiable. In a hospital setting, you need to know why an AI gave a specific recommendation.
The Llaama Standard: Every answer the Twin gives to a patient, and every insight it flags for a doctor, is fully traceable. We provide the "paper trail" for every decision, ensuring safety for patients and liability protection for providers.
Our Patient Digital Twin solution is build with the LLAAMA PLATFORM on top of our T2R2™ distributed multi-agent system which ensures ultimate Transparency, Treacabilitly, Reproducibility & Replicability.
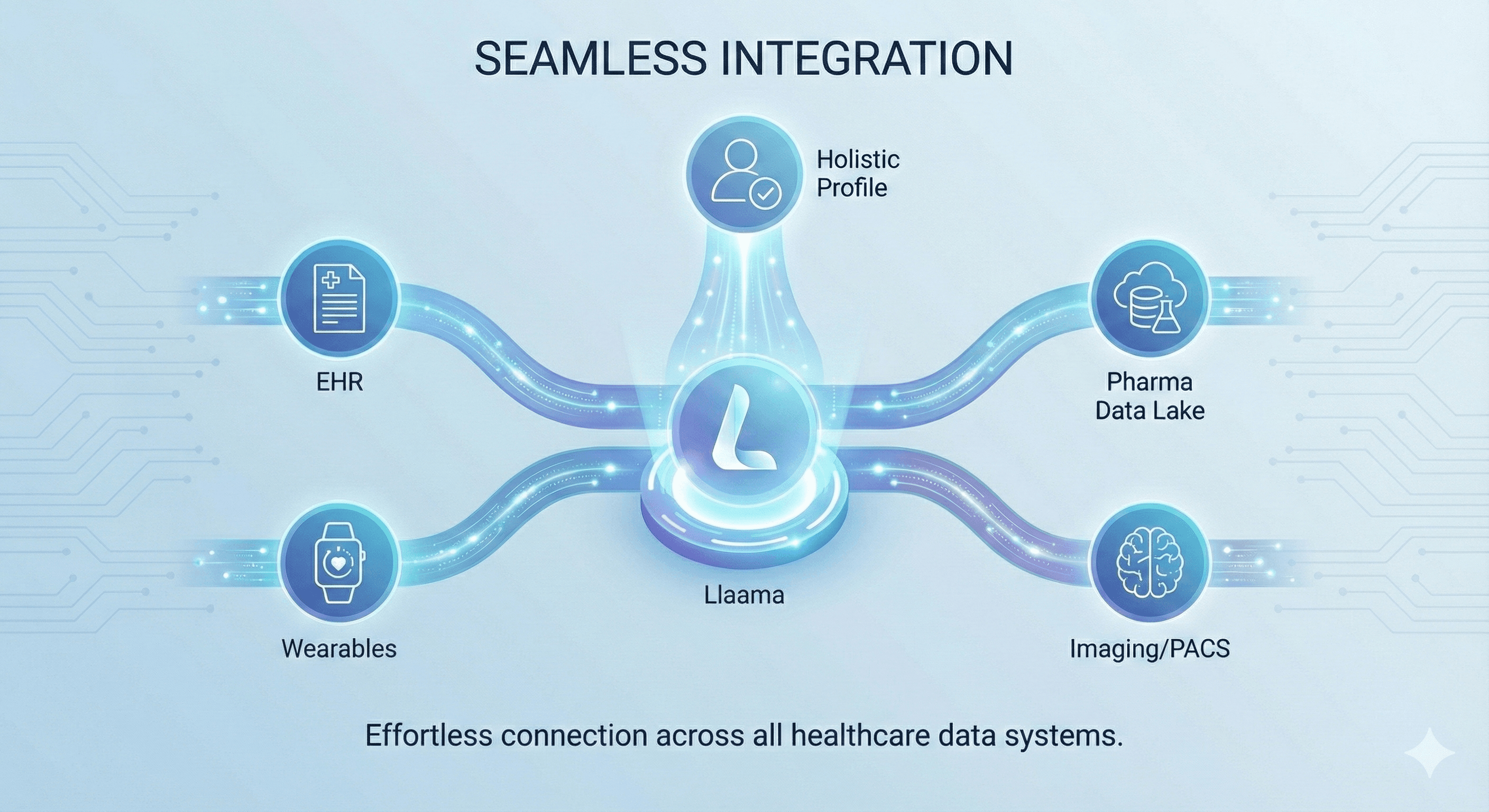
Seamless Integration
Works Where You Work. Whether it’s integrating with hospital EHR systems or Pharma data lakes, our platform is designed to fit your workflow.
It bridges the gap between raw medical data and the human beings who need to understand it.